CertificationService Delivery Program
AWS Glue
AWS Glue is a serverless data integration service that makes it easier to discover, prepare, move and integrate data from multiple sources for analytics, machine learning (ML), and application development. As an AWS Glue partner, Firemind can help you to build and manage a modern data pipeline with a single data integration service like Glue.
Overview
Keep costs low and focus more on your data at any scale with serverless data integration. You can use your favourite method: drag and drop, write code or connect using your notebook. AWS Glue supports various data processing methods and workloads, including ETL, ELT, batch and streaming.
AWS Glue uses other AWS services to orchestrate your ETL (extract, transform, and load) jobs to build data warehouses and data lakes and generate output streams. AWS Glue calls API operations to transform your data, create runtime logs, store your job logic, and create notifications to help you monitor your job runs. The AWS Glue console connects these services into a managed application, so you can focus on creating and monitoring your ETL work. The console performs administrative and job development operations on your behalf. You supply credentials and other properties to AWS Glue to access your data sources and write to your data targets.
AWS Glue takes care of provisioning and managing the resources that are required to run your workload. You don’t need to create the infrastructure for an ETL tool because AWS Glue does it for you. When resources are required, to reduce startup time, AWS Glue uses an instance from its warm pool of instances to run your workload.
Below is a typical architecture where AWS Glue shows data integration engine options. To view ETL, Glue Data Catalog and more, click here.
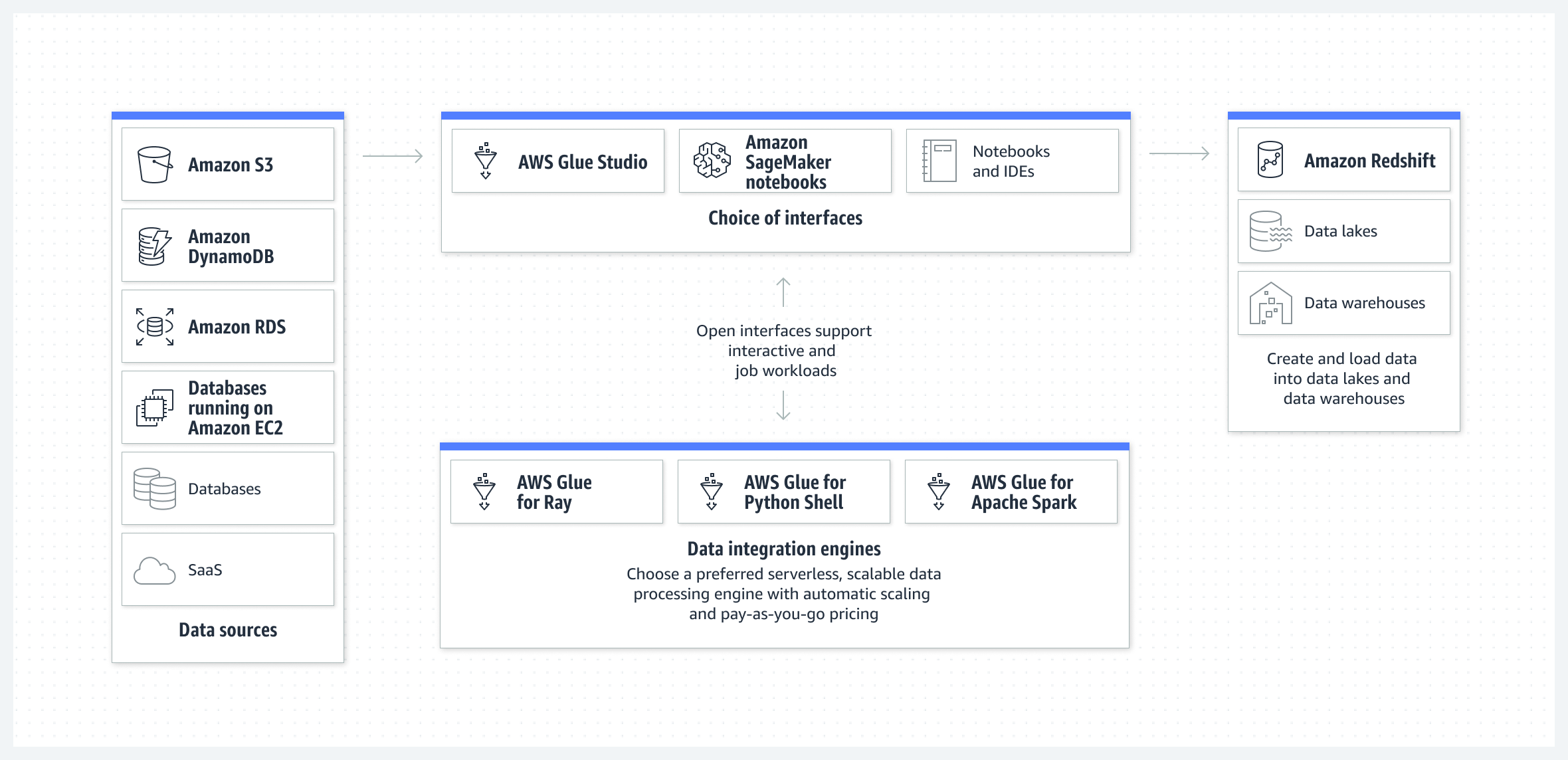
Remove infrastructure management with automatic provisioning and worker management, and consolidate all your data integration needs into a single service.
Quickly identify data across multiple AWS datasets, and then make it instantly available for querying and transforming.
Using AWS Glue interactive sessions, data engineers can interactively explore and prepare data using the integrated development environment (IDE) or notebook of their choice.
More easily support various data processing frameworks, such as ETL and ELT, and various workloads, including batch, micro-batch, and streaming.
With AWS Glue, you pay an hourly rate, billed by the second, for crawlers (discovering data) and ETL jobs (processing and loading data). For the AWS Glue Data Catalog, you pay a simple monthly fee for storing and accessing the metadata. The first million objects stored are free, and the first million accesses are free. If you provision a development endpoint to interactively develop your ETL code, you pay an hourly rate, billed per second. For AWS Glue DataBrew, the interactive sessions are billed per session and the DataBrew jobs are billed per minute. Usage of the AWS Glue Schema registry is offered at no additional charge.
Check the calculator here.
AWS Glue uses other AWS services to orchestrate your ETL (extract, transform, and load) jobs to build data warehouses and data lakes and generate output streams. AWS Glue calls API operations to transform your data, create runtime logs, store your job logic, and create notifications to help you monitor your job runs. The AWS Glue console connects these services into a managed application, so you can focus on creating and monitoring your ETL work. The console performs administrative and job development operations on your behalf. You supply credentials and other properties to AWS Glue to access your data sources and write to your data targets.
AWS Glue takes care of provisioning and managing the resources that are required to run your workload. You don’t need to create the infrastructure for an ETL tool because AWS Glue does it for you. When resources are required, to reduce startup time, AWS Glue uses an instance from its warm pool of instances to run your workload.
Below is a typical architecture where AWS Glue shows data integration engine options. To view ETL, Glue Data Catalog and more, click here.
Remove infrastructure management with automatic provisioning and worker management, and consolidate all your data integration needs into a single service.
Quickly identify data across multiple AWS datasets, and then make it instantly available for querying and transforming.
Using AWS Glue interactive sessions, data engineers can interactively explore and prepare data using the integrated development environment (IDE) or notebook of their choice.
More easily support various data processing frameworks, such as ETL and ELT, and various workloads, including batch, micro-batch, and streaming.
With AWS Glue, you pay an hourly rate, billed by the second, for crawlers (discovering data) and ETL jobs (processing and loading data). For the AWS Glue Data Catalog, you pay a simple monthly fee for storing and accessing the metadata. The first million objects stored are free, and the first million accesses are free. If you provision a development endpoint to interactively develop your ETL code, you pay an hourly rate, billed per second. For AWS Glue DataBrew, the interactive sessions are billed per session and the DataBrew jobs are billed per minute. Usage of the AWS Glue Schema registry is offered at no additional charge.
Check the calculator here.
Want to find out more?
Got questions? We’ve got answers! Find out how our team can get you up and running with AWS Glue.