This post explores how these models work, looking at the processes of tokenisation, embeddings, training, and fine-tuning. We’ll also cover a number of use cases, from content creation and translation to sophisticated chatbots and coding assistants.
However, as with any powerful tool, LLMs present challenges and ethical considerations that cannot be overlooked. Critical issues such as bias, misinformation, security and privacy concerns, and potential job displacement, are all covered towards the end of the post. Read on to learn about the complex world of LLMs, with an appreciation of their capabilities and an acknowledgement of their limitations.
How they work
Most of today’s state-of-the-art LLMs, such as OpenAI’s ChatGPT, are based on a neural network architecture called transformers. Transformers have proved particularly capable of capturing context in sequential data such as text. The main innovation of transformers – the attention mechanism – enables parallel processing, where all input tokens are processed simultaneously. This feature helps transformers learn long-range dependencies, where the distance between one word or phrase and another is not necessarily proportional to their relevance. For example, in the sentence “The cat, which already ate a fish, was not hungry”, transformers would “understand” that “the act” is more closely associated with the phrase “not hungry” despite the distance between it and “the cat” being greater than it and “a fish”.
There are several steps that need to be completed in order to get a performant language model. The first of these is preparing text data so that it is understandable to the model. This process is known as tokenisation, where the input text is broken down into individual words, subwords or characters. The level of tokenisation – words, subwords or characters – depends on the nature of the language, the characteristics of the model, the size of the dataset and the requirements of the task at hand. In English, for example, where words are often separated by spaces and the vocabulary size is manageable, word-level tokenisation can be efficient. On the other hand, in languages such as Chinese or Japanese where words are not separated by spaces, character-level tokenisation could be more useful. Larger datasets enable word-level tokenisation, while smaller datasets often require sub-word or character-level tokenisation.
After tokenisation, these tokens are mapped to numerical vectors in a process known as embeddings. These vectors or embeddings represent words in a high-dimensional space where the location and distance between vectors captures semantic meaning. For example, vectors for words with similar meanings are placed closer together. This method allows the model to understand and capture the nuances in meaning and context between different words. The embeddings are not manually assigned but learned during the model training process, continually adjusting to better represent the contextual relationships between words.
The next step is to train the model on the tokenised embeddings. Training is a crucial part of the process that allows LLMs to generate coherent and contextually relevant text. It’s during this phase that these models learn the intricate patterns of language, enabling them to understand and replicate human-like text.
Training an LLM is a supervised learning task. The model is fed a massive dataset composed of countless sequences of tokens. Each sequence serves as an example from which the model can learn. The aim is for the model to learn to predict the next token in a sequence, given all the previous tokens.
The dataset used for training these models typically consists of a large corpus of text. It can include books, websites, articles, and other forms of written text. The larger and more diverse the dataset, the better the model can learn the various nuances of human language.
LLMs have many millions or even billions of parameters – these are the parts of the model that are learned from the data. At the start of training, these parameters are initialised with random values. As the model is exposed to the training data, it adjusts these parameters to reduce the difference between its predictions and the actual data. This adjustment process is guided by a function called the loss function, which quantifies how well the model’s predictions match the actual data.
The primary technique used to adjust the model’s parameters is called backpropagation, used in conjunction with an optimisation algorithm like stochastic gradient descent. In simple terms, backpropagation calculates the gradient of the loss function with respect to the model’s parameters, indicating how much a small change in parameters would affect the loss. The parameters are then updated in the direction that reduces the loss, i.e. that increases the accuracy of the model’s predictions.
The process of updating the model’s parameters to minimise the loss is repeated across numerous iterations. An iteration refers to the model processing a batch of data and updating its parameters once. An epoch, on the other hand, refers to the model going through the entire dataset once. Training an LLM usually involves several epochs, which means the model sees the entire dataset multiple times.
A key challenge during training is avoiding overfitting, where the model learns the training data too well and performs poorly on unseen data. Techniques like regularisation, dropout, and early stopping are used to prevent overfitting.
The outcome of this rigorous training process is a model that can generate human-like text, answer questions, summarise texts, translate languages and write code, amongst. All by predicting what comes next in a sequence of tokens.
After the initial training, the model can be fine-tuned on specific tasks. For example, if you want to use the model for a medical chatbot, you can fine-tune it on medical text data. This helps the model perform better on specific tasks than it would if it only learned from general text data.
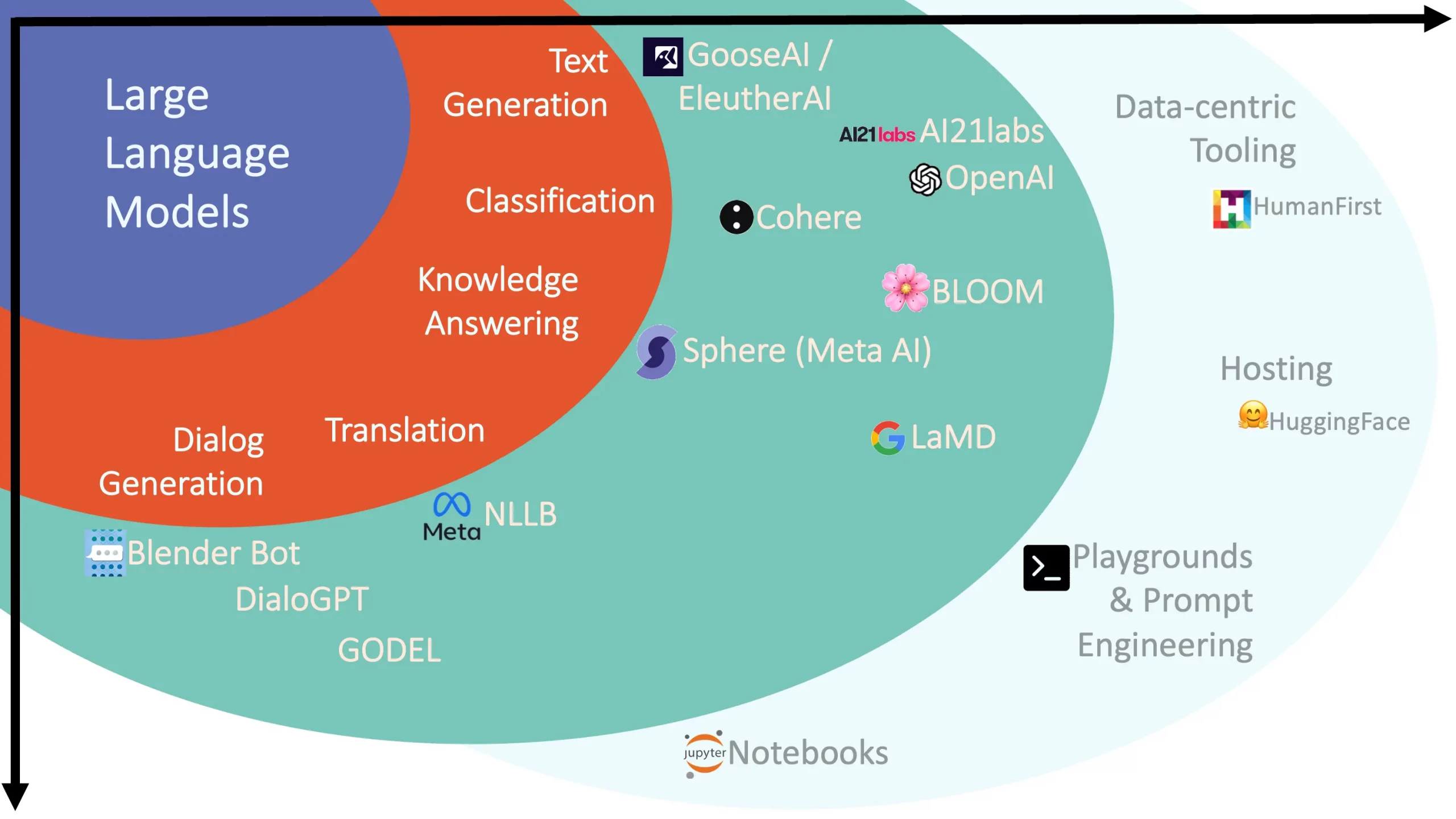
Use cases
The most significant impact of genAI is of course its ability to generate content. The rapid and widespread adoption of ChatGPT and other generative models is fundamentally because of the fact that they afford us more time. With their robust capabilities in understanding and generating text, these AI models can produce a range of content pieces – from articles and blog posts to creative stories and poetry. They can generate text that closely mirrors human writing, incorporating tones, styles, and context into their output. Whether you need help brainstorming ideas, drafting initial versions of your articles, or simply desire a tool that can continue your story given a prompt, LLMs are a powerful tool. They can even generate marketing copy, write emails, or create engaging social media posts. While they may not replace human creativity entirely, their ability to rapidly generate diverse content can provide significant support, enhancing productivity and fuelling new ideas. It’s like having an AI-powered co-writer at your disposal, ready to aid in your creative processes at any time.
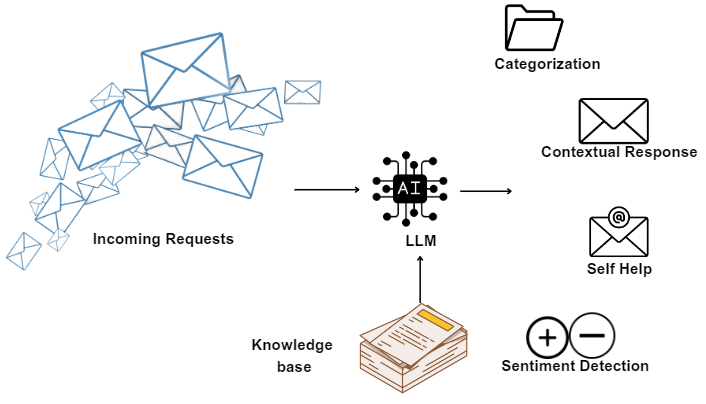
LLMs have proven instrumental in revolutionising the capabilities of question-answering. By understanding the intricate nuances of language, they can comprehend a wide range of questions and generate accurate, contextually appropriate answers. This has given rise to a new generation of customer service bots that can handle complex queries, reducing the need for human intervention and significantly improving response times. Beyond customer service, these models are being used to develop advanced tutoring systems that can provide personalised answers to student queries, akin to having a personal tutor available on-demand. As LLMs continue to evolve, question-answering systems are bound to become even more sophisticated, further blurring the lines between human and AI-driven interactions. It’s a promising sign of the transformative potential these models have in reshaping digital communication.
Chatbots powered by LLMs are redefining the dynamics of human-machine interaction. These advanced models understand and generate text that closely emulates human conversation, driving the creation of more natural, interactive, and engaging chatbots. Whether it’s answering customer queries, providing product recommendations, or assisting with bookings, LLM-driven chatbots can handle a myriad of tasks across industries. They’ve significantly improved user experience by providing immediate and personalised responses around the clock, without the typical constraints of human-operated customer service. Moreover, these intelligent chatbots are capable of maintaining context over extended conversations, making interactions feel less mechanical and more like a human conversation. As LLMs continue to improve, we can expect chatbots to become even more integrated into our daily digital interactions, providing efficient, personalised, and user-friendly services.
The domain of language translation has also witnessed significant advancements with the advent of LLMs. These models demonstrate a reasonable proficiency in translating text from one language to another. Thanks to their immense training on diverse and multilingual datasets, they can recognise and adapt to different linguistic structures, idioms, and context. While they might not yet match the precision of dedicated translation systems for complex texts, they do provide quick, on-the-fly translations for simpler, less technical texts. This makes LLMs a versatile tool, capable of bridging language barriers and enabling smoother cross-lingual communication. As these models continue to evolve, we can expect their translation capabilities to improve, potentially opening up new opportunities for real-time, context-aware translation services.
LLMs also hold substantial promise in the area of summarisation. Given a lengthy piece of text, these models can generate a concise and coherent summary that encapsulates the main points. This makes them a potential game-changer in a number of fields. For instance, LLMs can distil lengthy news articles into digestible summaries, allowing readers to grasp key information in a fraction of the time. Similarly, in academic research or legal proceedings where one may need to sift through extensive documents, LLMs can generate summaries that highlight the core arguments or findings, significantly reducing the time and effort required for review. The true potential of this application is vast, spanning across journalism, academia, law, business, and much more. As the technology is refined, we could witness an evolution in how we manage and consume information, making the process more efficient and accessible.
Another application of LLMs is software development. By being trained on massive datasets of code as well as natural language, they have the ability to both generate and review code. This is an invaluable asset for developers. For instance, given a high-level description of a function, LLMs can generate a rough draft of corresponding code, effectively serving as an programming assistant. Github has previewed Copilot X, a pair programmer powered by OpenAI’s Codex. Copilot X will be able to complete, refactor, lint and review code in a number of different programming languages. In terms of code review, these models can help identify bugs, suggest improvements, and enforce style guides, contributing to the quality and efficiency of software development. While LLMs are not yet capable of replacing human developers, they can provide significant assistance, automating routine tasks and freeing up time for more complex, creative problem-solving. As these models are continuously refined and trained, their impact on the software development landscape is likely to be transformative.
Challenges and ethical considerations
One of the most significant challenges with LLMs is the risk of biases in their outputs. These models learn from vast datasets typically collected from the internet, which can contain biased and prejudiced information. As a result, the models may unwittingly learn and perpetuate these biases. For example, they might generate gender-biased language or reinforce harmful stereotypes. The effects of such biases can be far-reaching, especially when these models are used in decision-making systems or for generating content that is widely spread. Addressing this challenge involves conscientious efforts in data curation, model testing, and implementing measures to mitigate identified biases.
Another significant challenge is the potential propagation of misinformation. LLMs generate content based on patterns learned from their training data and do not have an inherent understanding or verification of truth. This implies that if prompted or inclined to, these models could generate content that is factually incorrect or misleading. This is a critical concern because of the serious consequences that misinformation can have. One potential solution could involve incorporating mechanisms to cross-verify generated content with reliable data sources, but the implementation of such systems is far from trivial.
As with any technology handling data, especially data of a personal or sensitive nature, security and privacy are paramount. Ensuring that LLMs are used ethically and securely is a crucial consideration. This includes safeguarding the data used for training and maintaining privacy in applications where user data is involved, such as in personalised chatbots or recommendation systems. It also covers concerns about the malicious use of LLMs, for example, in generating deepfake content or deceptive information.
The fear of AI resulting in job displacement is a common concern, and LLMs are no exception. As these models become more capable of generating high-quality content and handling tasks such as customer service, there is a concern that they could replace human jobs in these sectors. While AI can automate routine tasks it is important to remember that it also creates new opportunities and roles that didn’t exist before; consider, for example, the rise of prompt engineering. The challenge lies in managing this transition, including providing necessary upscaling and reskilling opportunities to help individuals adapt to the changing job landscape.
Navigating these challenges and ethical considerations will be a key part of the journey as we continue to develop and deploy LLMs. It underscores the need for multidisciplinary collaboration, including policymakers, researchers, ethicists, and users, to ensure that the development of this powerful technology is guided by principles of fairness, transparency, and accountability.
Conclusion
As we’ve explored, LLMs are formidable tools with enormous potential that have already transformed a wide range of fields. However, they are not a panacea, and their use comes with important considerations related to bias, misinformation, and other ethical concerns. As these models continue to be enhanced and are applied in new ways, it is important to remain vigilant about these issues, ensuring that the technology is developed and used responsibly.
We are still in the early days of understanding and harnessing the full potential of LLMs. With further research, ethical guidelines, and practical implementation, these models promise to continue driving significant advancements in AI. It is an exciting journey, and the possibilities are as broad as the collective imagination.
If you’d like to learn more about Firemind and our involvement with generative AI, visit our summary page here for further details.